Tech Drive : Archive tech diaries of beeyeas@gmail.com
APM ( Application Performance Management ) and Distributed Tracing...
Inspired by Dapper few below trending...
http://opentracing.io/documentation/ : A standard for tracing ( https://github.com/opentracing/specification/issues/86 )
https://github.com/jaegertracing/jaeger
https://github.com/jaegertracing
https://zipkin.io/
https://medium.com/opentracing/distributed-tracing-in-10-minutes-51b378ee40f1
Wednesday, February 7, 2018
WeaveScope for micro-service discovery and monitoring
Tech Drive : Archive tech diaries of beeyeas@gmail.com
Weave Scope (https://github.com/weaveworks/scope) is the one tool i have been using for a while and forgot to jot it here...
Pretty well done, and i still see activity in commits here
Funding : i see weavescope is well funded GV ( Google Ventures ) , sounds good on the whole
https://www.crunchbase.com/organization/weaveworks
Install : https://www.weave.works/docs/scope/latest/installing/
Weave Scope (https://github.com/weaveworks/scope) is the one tool i have been using for a while and forgot to jot it here...
Pretty well done, and i still see activity in commits here
Funding : i see weavescope is well funded GV ( Google Ventures ) , sounds good on the whole
https://www.crunchbase.com/organization/weaveworks
Install : https://www.weave.works/docs/scope/latest/installing/
sudo curl -L git.io/scope -o /usr/local/bin/scope
sudo chmod a+x /usr/local/bin/scope
scope launchSunday, June 4, 2017
Network Traffic Analysis
Goal :
Situation :
"Recently I needed some NetFlow data samples, I’ve looked all over the internet for some of those, but for obvious privacy reasons there were none. No one shares their NetFlow data. Not even a little sample. So what could I do, I had no Cisco equipments to generate traffic on and then to collect it in data flows. So I’ve improvised by using my laptop as a router in the campus network and collecting the traffic that went through it in data flows. This post is about how to generate and collect Netflow data on your own network."
Tools used :
/etc/default/softflowd file and define the INTERFACE and OPTIONS variables as follows:
#sudo softflowctl -c /var/run/softflowd.ctl statistics
#sudo softflowctl -c /var/run/softflowd.ctl expire-all
#nfdump -R /var/cache/nfdump/ | head -5
nfsen : A nice visualization tool for
Download nfsen-1.3.8 bundle
#tar -xvf nfsen-1.3.8.tar.gz
#cd nfsen-1.3.8/
Make sure you make a copy of nfsen.conf template and ready for editing it
#sudo ./install.pl etc/nfsen.conf
#sudo apt-get install rrdtool
#sudo ./install.pl etc/nfsen.conf
#perl -MCPAN -e 'install RRD::Simple'
#wget http://oss.oetiker.ch/rrdtool/pub/rrdtool-1.4.3.tar.gz
#gunzip -c rrdtool-1.4.3.tar.gz | tar xf -
#cd rrdtool-1.4.3/
#sudo apt-get install libpangol.0-dev libxml2-dev
#sudo apt-get install libpangol.O-dev libxml2-dev
#sudo apt-get install libpango1.0-dev libxml2-dev
#./configure --prefix=$INSTALL_DIR && make && make install
#sudo ./configure --prefix=$INSTALL_DIR && make && make install
#sudo ./install.pl etc/nfsen.conf
#sudo ./install.pl etc/nfsen.conf
#aptitude install rrdtool librrd2-dev librrd-dev librrd4 librrds-perl librrdp-perl
#sudo aptitude install rrdtool librrd2-dev librrd-dev librrd4 librrds-perl librrdp-perl
#sudo apt-get install php5
#netstat -autn | grep -i listen
#vi etc/nfsen.conf
#sudo useradd -d /var/netflow -G www-data -m -s /bin/false netflow
#sudo perl install.pl etc/nfsen.conf
#vi etc/nfsen.conf
#sudo perl install.pl etc/nfsen.conf
#sudo instmodsh
#sudo perl -MCPAN -e 'install Mail::Header'
#sudo perl install.pl etc/nfsen.conf
#sudo perl -MCPAN -e 'install Socket6'
#sudo perl install.pl etc/nfsen.conf
#sudo ps -ef | grep nfsen
#sudo ./nfsen start
Enable apache2.conf for nfsen web folders
#sudo nano /etc/apache2/sites-available/000-default.conf
#sudo vi /etc/apache2/apache2.conf
References :
- Generate netflow traffic (simulator) in linux box
- Map the generated data as visual graphs
Situation :
"Recently I needed some NetFlow data samples, I’ve looked all over the internet for some of those, but for obvious privacy reasons there were none. No one shares their NetFlow data. Not even a little sample. So what could I do, I had no Cisco equipments to generate traffic on and then to collect it in data flows. So I’ve improvised by using my laptop as a router in the campus network and collecting the traffic that went through it in data flows. This post is about how to generate and collect Netflow data on your own network."
Tools used :
- softflowd : https://github.com/davidediger/softflowd : Netflow generator daemon
- nfdump : https://github.com/phaag/nfdump : Netflow dump
- nfsen : https://github.com/sown/nfsen : Visualization tool for nfdump
# apt-get install softflowd
INTERFACES = "any" OPTIONS = "-n 127.0.0.1:9995"
# /etc/init.d/softflowd start
If you don’t want to wait for the flows to expire, you may force them to by running this:
# softflowd -c /var/run/softflowd.ctl expire-all
nfdump - install and test the collector
The nfdump package is a suite of tools, one of which is nfcapd, which is the collector, and nfdump which is the display and analysis program. There are some other tools included as well, but those are the major commands we need to know about. To install nfdump run:
# apt-get install nfdump
# nfcapd -D -l /var/cache/nfdump
# lsof -Pni | grep nfcapd
We should wait awhile for some data to be produced, but to see what that data looks like we could run the following command:
# nfdump -R /var/cache/nfdump/ | head -5
Date first seen Duration Proto Src IP Addr:Port Dst IP Addr:Port Packets Bytes Flows
2015-09-10 18:45:05.243 0.000 UDP 158.121.23.138:59026 -> 158.121.23.255:8083 1 49 1
2015-09-10 18:45:08.107 0.000 UDP 158.121.22.94:68 -> 255.255.255.255:67 2 656 1
2015-09-10 18:42:29.532 161.807 UDP 158.121.23.0:68 -> 255.255.255.255:67 3 984 1
2015-09-10 18:45:08.458 4.103 UDP 158.121.22.94:137 -> 158.121.23.255:137 4 312 1
#sudo softflowctl -c /var/run/softflowd.ctl expire-all
#nfdump -R /var/cache/nfdump/ | head -5
nfsen : A nice visualization tool for
Download nfsen-1.3.8 bundle
#tar -xvf nfsen-1.3.8.tar.gz
#cd nfsen-1.3.8/
Make sure you make a copy of nfsen.conf template and ready for editing it
#sudo ./install.pl etc/nfsen.conf
#sudo apt-get install rrdtool
#sudo ./install.pl etc/nfsen.conf
#perl -MCPAN -e 'install RRD::Simple'
#wget http://oss.oetiker.ch/rrdtool/pub/rrdtool-1.4.3.tar.gz
#gunzip -c rrdtool-1.4.3.tar.gz | tar xf -
#cd rrdtool-1.4.3/
#sudo apt-get install libpangol.0-dev libxml2-dev
#sudo apt-get install libpangol.O-dev libxml2-dev
#sudo apt-get install libpango1.0-dev libxml2-dev
#./configure --prefix=$INSTALL_DIR && make && make install
#sudo ./configure --prefix=$INSTALL_DIR && make && make install
#sudo ./install.pl etc/nfsen.conf
#sudo ./install.pl etc/nfsen.conf
#aptitude install rrdtool librrd2-dev librrd-dev librrd4 librrds-perl librrdp-perl
#sudo aptitude install rrdtool librrd2-dev librrd-dev librrd4 librrds-perl librrdp-perl
#sudo apt-get install php5
#netstat -autn | grep -i listen
#vi etc/nfsen.conf
#sudo useradd -d /var/netflow -G www-data -m -s /bin/false netflow
#sudo perl install.pl etc/nfsen.conf
#vi etc/nfsen.conf
#sudo perl install.pl etc/nfsen.conf
#sudo instmodsh
#sudo perl -MCPAN -e 'install Mail::Header'
#sudo perl install.pl etc/nfsen.conf
#sudo perl -MCPAN -e 'install Socket6'
#sudo perl install.pl etc/nfsen.conf
#sudo ps -ef | grep nfsen
#sudo ./nfsen start
#sudo nano /etc/apache2/sites-available/000-default.conf
#sudo vi /etc/apache2/apache2.conf
References :
- All above are documented here : https://github.com/beeyeas/spark-playground/tree/master/netflow
- nfsen : http://nfsen.sourceforge.net/#mozTocId778656
- http://elf11.github.io/2015/09/10/NetFlows-data-generation.html
- http://meetings.ripe.net/ripe-50/presentations/ripe50-plenary-tue-nfsen-nfdump.pdf
- https://farisy18.wordpress.com/tag/rrdtool/
Wednesday, April 19, 2017
Scalable SQL like data store ( cockroach DB )
I happened to try something cool this week, where the traditional SQL databases failed to solve these challenges.
MySQL, Postgres or Oracle all have HA and replication, backup and recovery but these are still a huge monolith of data stores spanning huge volumes of disks.
The traditional way of solving these would be the sharding of db ( db-federation ) ...segregating reads and write to different instances ( PS : https://www.brentozar.com/articles/sharding/)
Scale up : is to load a server instance with more resources (CPU, Memory ... )
Scale out : is to create more instance of server ( this needs sufficient network pipe ...)
Scale out solution with db sharding could be of 3 choices
1. Range Partitoning
2. List Partitioning
3. Consistent Hashing ( wow, i learned this in the context of load balancer )
Now, with all these traditional approaches.
How distributed systems could solve this elegantly ( how i got glued to cockroachDB )
2. Start the first cockroach DB node
#docker run -d --name=roach1 --hostname=roach1 --net=roachnet -p 26257:26257 -p 8080:8080 -v "${PWD}/cockroach-data/roach1:/cockroach/cockroach-data" cockroachdb/cockroach:beta-20170413 start --insecure
3. Start the second cockroach DB node
#docker run': docker run -d --name=roach2 --hostname=roach2 --net=roachnet -v "${PWD}/cockroach-data/roach2:/cockroach/cockroach-data" cockroachdb/cockroach:beta-20170413 start --insecure --join=roach1
4.Start the third cockroach DB node
#docker run': docker run -d --name=roach3 --hostname=roach3 --net=roachnet -v "${PWD}/cockroach-data/roach3:/cockroach/cockroach-data" cockroachdb/cockroach:beta-20170413 start --insecure --join=roach1
Voila , cockroachDB with 3 nodes are up and running
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e1940aab526f cockroachdb/cockroach:beta-20170413 "/cockroach/cockro..." 46 hours ago Up 46 hours 8080/tcp, 26257/tcp roach3
93939da8b5f8 cockroachdb/cockroach:beta-20170413 "/cockroach/cockro..." 46 hours ago Up 46 hours 8080/tcp, 26257/tcp roach2
466fd24c9720 cockroachdb/cockroach:beta-20170413 "/cockroach/cockro..." 46 hours ago Up 46 hours 0.0.0.0:8080->8080/tcp, 0.0.0.0:26257->26257/tcp roach1
MySQL, Postgres or Oracle all have HA and replication, backup and recovery but these are still a huge monolith of data stores spanning huge volumes of disks.
The traditional way of solving these would be the sharding of db ( db-federation ) ...segregating reads and write to different instances ( PS : https://www.brentozar.com/articles/sharding/)
Scale up : is to load a server instance with more resources (CPU, Memory ... )
Scale out : is to create more instance of server ( this needs sufficient network pipe ...)
Scale out solution with db sharding could be of 3 choices
1. Range Partitoning
2. List Partitioning
3. Consistent Hashing ( wow, i learned this in the context of load balancer )
Now, with all these traditional approaches.
How distributed systems could solve this elegantly ( how i got glued to cockroachDB )
Cloud spanner :
- is from google, its is a light weight distributed data store which can be SQL queried.
- Release in early 2017 , a quite internal customer inside google for many years
- Has libraries for go, java, nodes, python
CockroachDB :
- A on-prem solution is from cockroach labs https://github.com/cockroachdb/cockroach
- Light weight go-lang implementation uses confesses protocol in the backend , gossip and raft.
- Very easy to set up , can start as docker over the docker network bridge
- These guys are from google who did spanner implementation for google, lets hope for the best
Amazon Athena :
- Is a similar SQL based distributed data store , but it is server less.
- Metered only when query is fired on data sets.
- Cool editor to handle SQL queries , handed data from S3 buckets
How easy to get started with cockroach DB ?
1.Create a docker network "roachnet"
#docker network create -d bridge roachnet
#docker run -d --name=roach1 --hostname=roach1 --net=roachnet -p 26257:26257 -p 8080:8080 -v "${PWD}/cockroach-data/roach1:/cockroach/cockroach-data" cockroachdb/cockroach:beta-20170413 start --insecure
3. Start the second cockroach DB node
#docker run': docker run -d --name=roach2 --hostname=roach2 --net=roachnet -v "${PWD}/cockroach-data/roach2:/cockroach/cockroach-data" cockroachdb/cockroach:beta-20170413 start --insecure --join=roach1
4.Start the third cockroach DB node
#docker run': docker run -d --name=roach3 --hostname=roach3 --net=roachnet -v "${PWD}/cockroach-data/roach3:/cockroach/cockroach-data" cockroachdb/cockroach:beta-20170413 start --insecure --join=roach1
Voila , cockroachDB with 3 nodes are up and running
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e1940aab526f cockroachdb/cockroach:beta-20170413 "/cockroach/cockro..." 46 hours ago Up 46 hours 8080/tcp, 26257/tcp roach3
93939da8b5f8 cockroachdb/cockroach:beta-20170413 "/cockroach/cockro..." 46 hours ago Up 46 hours 8080/tcp, 26257/tcp roach2
466fd24c9720 cockroachdb/cockroach:beta-20170413 "/cockroach/cockro..." 46 hours ago Up 46 hours 0.0.0.0:8080->8080/tcp, 0.0.0.0:26257->26257/tcp roach1
Wednesday, April 5, 2017
Deploying Influx TICK Stack on K8
My goal here is to stand-up TICK stack for monitoring K8-clusters
Reference : https://www.influxdata.com/how-to-spin-up-the-tick-stack-in-a-kubernetes-instance/
Follow here https://github.com/influxdata/tick-charts
Kubernetes Dashboard showing TICK stack after HELM Deployment






Follow here https://github.com/influxdata/tick-charts
Kubernetes Dashboard showing TICK stack after HELM Deployment






Friday, March 3, 2017
K8 (Kube) Package Manager - Helm
I see helm as analogous to AWS Cloud Formation
https://github.com/kubernetes/helm
Helm is the package manager for kubenetes. It in-turn uses kubenetes charts .

https://github.com/kubernetes/helm
Helm is the package manager for kubenetes. It in-turn uses kubenetes charts .
Helm is a tool for managing Kubernetes charts. Charts are packages of pre-configured Kubernetes resources.
Use Helm to...
- Find and use popular software packaged as Kubernetes charts
- Share your own applications as Kubernetes charts
- Create reproducible builds of your Kubernetes applications
- Intelligently manage your Kubernetes manifest files
- Manage releases of Helm packages

Helm is the tool to load charts into K8 for application deployment
Thursday, March 2, 2017
WTF is "Open Source Core"
I recently came across this term and it sounds cool and practical to me.
Thought of sharing it here, as i suddenly realized i have this in my screen all over...
Example : Look at https://www.influxdata.com/products/ , formerly influx DB.
They have real good products (influxcloud, influxEnterprise, TICK stack), inturn all of these are just one "A Real-Time Monitoring Solution"
In data center we host tons of application and we need a true solution for monitoring, there are tons of monitoring solutions datadog, new relic, etc... but all are closed products.
The power of "Open Source Core" is the whole complex product is open sourced ( githubbed )
, but the niche feature to take it to enterprise or integrate will be the monetizing way.
That is , in this example Influx Enterprise is the Monetizing product.
Another example : Hashicorp
https://www.hashicorp.com/
Famously called "Hashi-stack", open sourced all their core complex products.
Vagrant, Packer, Vault, Consul, Terraform. But their enterprise version and another niche product atlas is their monetizing product.
https://overcast.fm/+HZUc5QQ4k/35:07
Thought of sharing it here, as i suddenly realized i have this in my screen all over...
Example : Look at https://www.influxdata.com/products/ , formerly influx DB.
They have real good products (influxcloud, influxEnterprise, TICK stack), inturn all of these are just one "A Real-Time Monitoring Solution"
In data center we host tons of application and we need a true solution for monitoring, there are tons of monitoring solutions datadog, new relic, etc... but all are closed products.
The power of "Open Source Core" is the whole complex product is open sourced ( githubbed )
, but the niche feature to take it to enterprise or integrate will be the monetizing way.
That is , in this example Influx Enterprise is the Monetizing product.
Another example : Hashicorp
https://www.hashicorp.com/
Famously called "Hashi-stack", open sourced all their core complex products.
Vagrant, Packer, Vault, Consul, Terraform. But their enterprise version and another niche product atlas is their monetizing product.
https://overcast.fm/+HZUc5QQ4k/35:07
Mesosphere DC/OS installation
I am playing around with DC/OS and tried to install it on GCE ( Google Cloud Engine )
I blindly followed https://dcos.io/docs/1.8/administration/installing/cloud/gce/#configure
and saw stars at the end ( well, spinning around my head ) .
Not so good documentation, end result : "nothing works"
I was hoping i will improve this documentation with my experience of installing in GCE, but i failed miserably , could not achieve what i want to do.
Ok, what really happened
I followed the instruction in DC/OS documentation but could not get the DC/OS up and running.
1. https://dcos.io/docs/1.8/administration/installing/cloud/gce/#bootstrap :
Easy and got this working
2. https://dcos.io/docs/1.8/administration/installing/cloud/gce/#install :
These are ansible powered and calls GCE API to provision a master0 node and then agent-nodes, all works fine with slight tweek to ansible, it did not run the first time as documented.
3. https://dcos.io/docs/1.8/administration/installing/cloud/gce/#configure : Failed
I wanted to be sure if i really installed DC/OS stack and was i successful?
I could not see the mesos, marathon or DCOS. Err:FAILED.
All i have done so far is bring up 3 VMs in my GCE.
I wish this document gets better and a cleaner support ....
BTW : A good pod to listen to https://overcast.fm/+I_rT72mY/41:07
I blindly followed https://dcos.io/docs/1.8/administration/installing/cloud/gce/#configure
and saw stars at the end ( well, spinning around my head ) .
Not so good documentation, end result : "nothing works"
I was hoping i will improve this documentation with my experience of installing in GCE, but i failed miserably , could not achieve what i want to do.
Ok, what really happened
I followed the instruction in DC/OS documentation but could not get the DC/OS up and running.
1. https://dcos.io/docs/1.8/administration/installing/cloud/gce/#bootstrap :
Easy and got this working
2. https://dcos.io/docs/1.8/administration/installing/cloud/gce/#install :
These are ansible powered and calls GCE API to provision a master0 node and then agent-nodes, all works fine with slight tweek to ansible, it did not run the first time as documented.
3. https://dcos.io/docs/1.8/administration/installing/cloud/gce/#configure : Failed
I wanted to be sure if i really installed DC/OS stack and was i successful?
I could not see the mesos, marathon or DCOS. Err:FAILED.
All i have done so far is bring up 3 VMs in my GCE.
I wish this document gets better and a cleaner support ....
BTW : A good pod to listen to https://overcast.fm/+I_rT72mY/41:07
Wednesday, March 1, 2017
How to run graylog cluster in GKE(Google Container Engine)
With reference to another article i wrote earlier on how to run graylog cluster in kubenetes here ( http://beeyeas.blogspot.com/2017/02/how-to-run-graylog-cluster-in-kubernetes.html) , it was the way to run graylog ( mongo, elastic and graylog server) to-gether in one single container instance in minikube.
Here i take another attempt to run micro-services container of mongodb, elastic-search and graylog2 in google cloud platform - google container engine( GKE )
Step1 : See here (http://beeyeas.blogspot.com/2017/02/gke-google-container-engine.html) , how to bring up GKE ( kubenetes instance )
I assume, you followed the instructions here correctly and have "kubectl" CLI configured correctly to point to your gcloud GKE instance.
Make sure you can access kubenetes dashboard , for which you have to proxy service
#kubectl proxy
Step 2 : get the kubenetes service and deployment files here ( https://github.com/beeyeas/graylog-kube ), clone repo
Step 3 : Create mongo, elasticsearch, graylog
#kubectl create -f mongo-service.yaml,mongo-deployment.yaml
#kubectl create -f elasticsearch-deployment.yaml,elasticsearch-service.yaml
#kubectl create -f graylog-deployment.yaml,graylog-service.yaml
Step 4 : forward graylog UI to local 19000 port
#kubectl port-forward graylog-2041601814-5qnbc 9000:9000
Step 5 : Verify if all services are up
#kubectl get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch None <none> 55555/TCP 1h
graylog 10.3.248.24 <none> 9000/TCP,12201/TCP 1h
kubernetes 10.3.240.1 <none> 443/TCP 1d
mongo None <none> 55555/TCP 1h
NOTE: Access localhost:9000 for graylog UI
Step 6 : Graylog UI is empty and do not have any logs to index or show , i have exposed port number 12201. Create a port forward for graylog input GELF HTTP
Make sure you got this screen configured in graylog, configurig GELF-HTTP in graylog
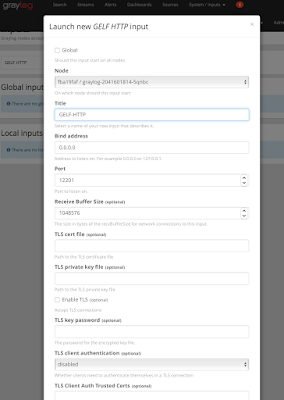
#kubectl port-forward graylog-2041601814-5qnbc 12201:12201
for i in {1..100000}; do curl -XPOST 127.0.0.1:12201/gelf -p0 -d '{"short_message":"Hello there", "host":"example.org", "facility":"test", "_foo":"bar"}'; done
After step 7 where you pump the logs, see if logs are showing up in the graylog UI

Here i take another attempt to run micro-services container of mongodb, elastic-search and graylog2 in google cloud platform - google container engine( GKE )
Step1 : See here (http://beeyeas.blogspot.com/2017/02/gke-google-container-engine.html) , how to bring up GKE ( kubenetes instance )
I assume, you followed the instructions here correctly and have "kubectl" CLI configured correctly to point to your gcloud GKE instance.
Make sure you can access kubenetes dashboard , for which you have to proxy service
#kubectl proxy
Step 2 : get the kubenetes service and deployment files here ( https://github.com/beeyeas/graylog-kube ), clone repo
Step 3 : Create mongo, elasticsearch, graylog
#kubectl create -f mongo-service.yaml,mongo-deployment.yaml
#kubectl create -f elasticsearch-deployment.yaml,elasticsearch-service.yaml
#kubectl create -f graylog-deployment.yaml,graylog-service.yaml
Step 4 : forward graylog UI to local 19000 port
#kubectl port-forward graylog-2041601814-5qnbc 9000:9000
Step 5 : Verify if all services are up
#kubectl get services
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch None <none> 55555/TCP 1h
graylog 10.3.248.24 <none> 9000/TCP,12201/TCP 1h
kubernetes 10.3.240.1 <none> 443/TCP 1d
mongo None <none> 55555/TCP 1h
NOTE: Access localhost:9000 for graylog UI
Step 6 : Graylog UI is empty and do not have any logs to index or show , i have exposed port number 12201. Create a port forward for graylog input GELF HTTP
Make sure you got this screen configured in graylog, configurig GELF-HTTP in graylog

#kubectl port-forward graylog-2041601814-5qnbc 12201:12201
Step 7 : Now we can pump some test log statements into graylog from localhost
After step 7 where you pump the logs, see if logs are showing up in the graylog UI

Tuesday, February 28, 2017
GKE - Google Container Engine
Google Container (with K) Engine aka GKE is a container solution from google cloud platform (GCP)
#kubectl get namespaces
- GCP : https://cloud.google.com/container-engine/
- Kubernetes undeneath
- MS-Azure : https://azure.microsoft.com/en-us/services/container-service/
- Docker swarm
- DC/OS
- Kubenetes
- Amazon AWS : http://docs.aws.amazon.com/AmazonECS/latest/developerguide/ECS_instances.html
How to start with GKE?
- I assume you have a cloud.google.com account signed up with your gmail account, need credit card (but $300 credit) for 60 days
- https://cloud.google.com/container-engine/

- View My Console

- Remember to download "gcloud" https://cloud.google.com/sdk/docs/quickstart-mac-os-x
- My cluster is called "kubecluster-1"
- Once i have gcloud init and installed , set up the auth by gcloud auth list
- Sample kubectl command shows it works

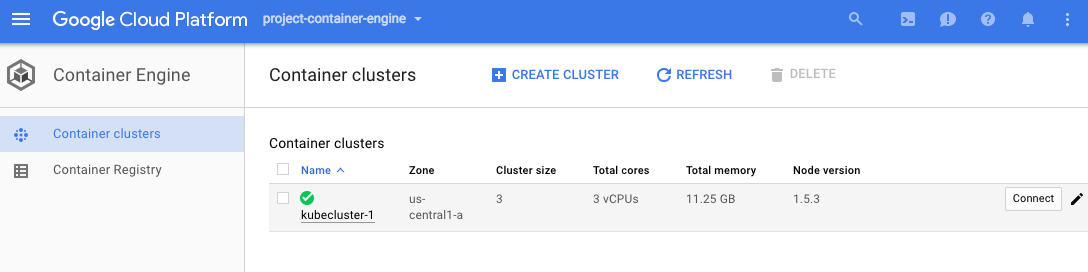
NAME STATUS AGE
default Active 1h
kube-system Active 1h
voila, kube is up
Subscribe to:
Posts (Atom)